AudioToken: Adaptation of Text-Conditioned Diffusion Models for Audio-to-Image Generation
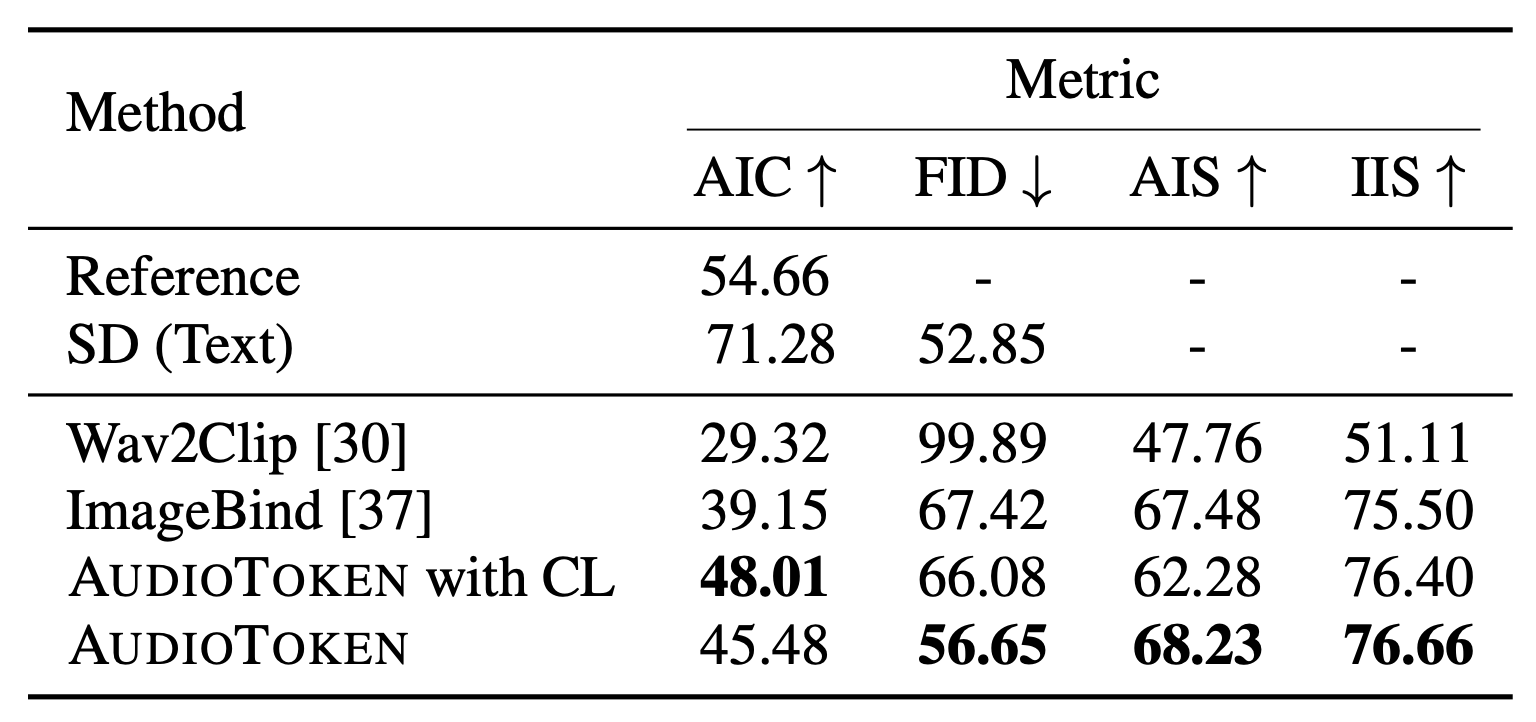
‘BEATs’라는 pre-trained audio classification network를 사용
이를 textual embedding space로 projection 하는 MLP와 attentive pooling layer 학습시켜 통과되어 나온 audio embedding을 ‘a photo of a’ token들 뒤에다가 붙임
두 개의 Linear layer + GELU non-linear activation function
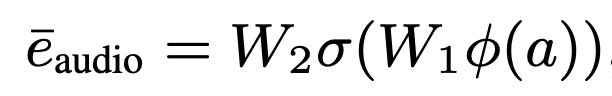

해당 text를 text-encoder로 CLIP embedding 생성 후 이를 T2I model의 cross-attention layer에 injection
Training은 일반적인 Conditioned diffusion model의 loss + Classification loss
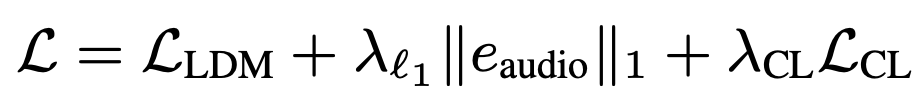
일반적인 Diffusion Model에서의 Loss (𝜏는 conditioning을 위한 encoder)
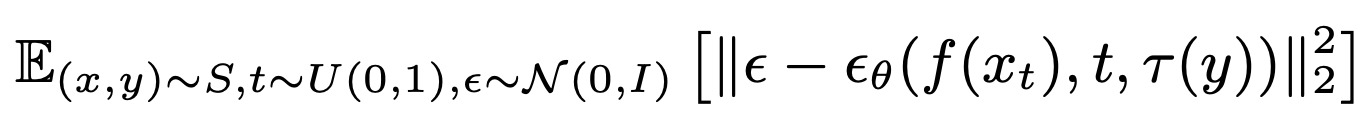
audio embedding과 데이터의 label의 유사도가 높아지도록 하는 loss
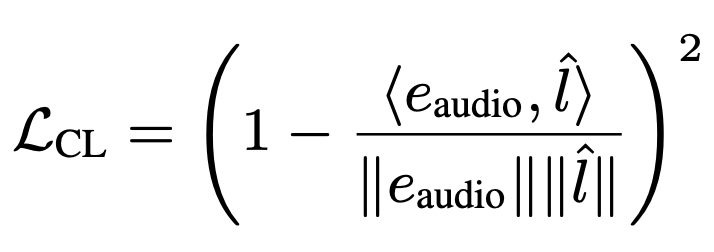
Pre-trained 모델들은 frozen 시키고 새롭게 추가한 layer들만 학습시킴