- These notes were prepared while studying for technical interviews (e.g., Snap Inc., KRAFTON, etc.).
- Each entry contains a concise English summary, key math expressions, and excerpts from my original handwritten/typed study notes.
These notes cover the linear-algebra machinery behind ML: vector-space structure, curvature, similarity, and the matrix decompositions used in optimization, compression, and dimensionality reduction.
Basics
Linearity

- the operation preserving addition and scalar multiplication
- allows models to be analyzed using linear algebra
- makes optimization more tractable
- linear models → convex objectives
- nonlinearity can be added via activation functions
Basis

- a set of linearly independent vectors spanning a vector space
- defines a coordinate system for representing vectors
- special bases: eigenvectors, singular vectors
- eigen decomposition ≃ change of basis
Rank
![]()
- dimension of the space spanned by the columns (or rows) of a matrix
- intrinsic dimensionality of a transformation
- number of linearly independent columns (or rows)
Hessian

- matrix of second-order partial derivatives
- can capture curvature information of the loss surface
- Symmetric matrix
- equal to its transpose
- all eigenvalues → real numbers
- all eigenvectors → orthogonal basis
Pseudo-Inverse

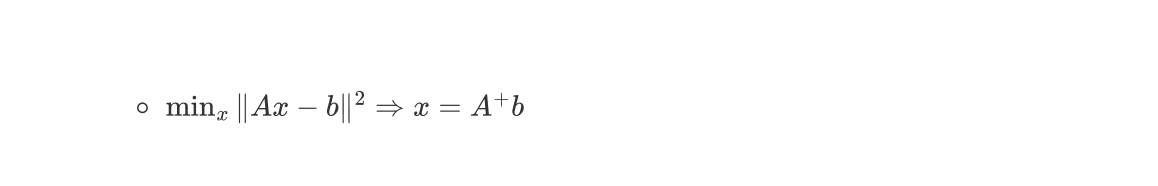
- applicable to any non-square matrix
- standard inverse matrix → requires full rank & square matrix
- defined via SVD ($A^+$)
- $A = U \Sigma V^\top, \quad A^+ = V \Sigma^+ U^\top$
- $\Sigma^+$: invert only nonzero singular values
- gives a solution to a minimum-squares problem
Determinant

- a scalar value associated with a square matrix
- measures volume scaling of a linear transformation
- determinant = 0 ⇔ rank-deficient ⇔ non-invertible
- from eigen decomposition → determinant = product of eigenvalues
Taylor Expansion

- local approximation of a function using its derivatives
- around a point using polynomial terms
- first-order (linear approximation)
- $f(x) \approx f(x_0) + \nabla f(x_0)^\top (x - x_0)$
- giving the direction of steepest local change
- second-order (quadratic approximation)
- capture curvature by using Hessian
- Newton method
- $w_{t+1} = w_t - H^{-1} \nabla \mathcal{L}(w_t)$
- Hessian matrix $H$ of loss function → eigenvalue ≃ steepness
- able to control the step size
- steep ↑ → size ↓
- v.s. Gradient descent
- gradient descent: single learning rate for all directions
- advantage: zig-zag ↓ & quadratic convergence ↑
- drawback: computation of second-order matrix ↑
Norms & Similarity
L2 Norm

- Euclidean distance
- smooth → differentiable
- discourages large weights → stable optimization
- may be sensitive to outliers
- Gaussian prior (MAP perspective)
L1 Norm

- promotes sparsity
- useful where there are few features
- implicit feature selection → robust to outliers but unstable optimization
- non-differentiable at 0
- Laplace prior (MAP perspective)
Cosine Similarity


- measure how aligned or related two vectors are
- focus on directions (rather than magnitude)
- scale-invariant: invariant to absolute scale
- valid range from $-1$ to $1$
- v.s. dot product
- dot product is affected by magnitude
- cons
- unstable if vector norm is very small
- less discriminative in dense representations (many vectors have similar angles)
Manifold

- space that is locally Euclidean → approximated by a tangent plane
- tangent vectors: derivatives of curves
- like a linear subspace in a sufficiently small neighborhood
- real-world data → on a much lower-dimensional manifold within a high-dimensional space
- explaining why dimensionality reduction & representation learning works
Kernel

- function that computes inner products in an implicit feature space
- without explicitly mapping data into the high-dimensional feature space
- implications
- many problems become linearly separable in a higher-dimensional space
- allow measuring similarity in a high-dimensional space efficiently
- without paying the computational cost of explicit feature expansion
Matrix Decomposition

- decomposing a matrix into simpler components
- reveals principal directions and effective dimensionality
- useful for understanding optimization geometry and parameter efficiency
Diagonalization

- transforming a matrix into a diagonal form via a similarity transform
- diagonal matrix $D$
- contains scaling factors along independent directions
- change of coordinate system
- where the linear transformation becomes independent per dimension
- diagonalizable: the matrix has a full set of linearly independent eigenvectors
- allow per-direction analysis of curvature and step size
Eigen Decomposition


- $A = Q \Lambda Q^{-1}$
- applicable only to square matrices
- similar to a change of basis
- transforms the problem into independent directions
- Eigenvectors: principal directions of transformation
- Eigenvalues: scaling along each direction
- Hessian analysis: eigenvalues ≃ curvature
- second-order curvature from Taylor expansion
- along principal directions of the loss surface
- large eigenvalue → steep direction
- Hessian analysis: eigenvalues ≃ curvature
- Spectral Theorem
- any real symmetric matrix can be decomposed by eigen decomposition
- leftmost and rightmost matrices have orthonormal eigenvectors
- Hessian eigen decomposition
- any real symmetric matrix can be decomposed by eigen decomposition
Singular Value Decomposition (SVD)

- $W = U \Sigma V^\top$
- sum of rank-1 component matrices, each weighted by a singular value
- applicable to any matrix
- singular vectors $U, V$: having orthonormal columns
- Singular values: importance (energy) of each rank-1 component
- Singular vectors: dominant input & output directions
- Truncated SVD
- keep top-$r$ singular values and corresponding singular vectors
- discard small singular values → often corresponding to noise
- suppress directions associated with small singular values
- optimal low-rank approximation that minimizes mean squared reconstruction error
- keep top-$r$ singular values and corresponding singular vectors
- widely used for compression and dimensionality reduction
- e.g., PCA (Principal Components Analysis)
Low-Rank Adaptation (LoRA)

- assumption: weight updates lie in a low-rank subspace
- instead of updating the full weight matrix
- freezing pretrained weight matrix $W_0$
- updating $\Delta W = BA$ with a small rank $r$:
- concentrating on a few dominant directions
- keeps top singular components (SVD perspective)
- captures the most important adaptation directions efficiently
- memory-efficient training, fine-tuning large pretrained models
Principal Component Analysis (PCA)

- a linear dimensionality reduction technique
- addresses the observation that
- high-dimensional data often lies near a low-dimensional subspace
Goals
- represent data with fewer dimensions
-
while preserving as much information as possible
- PCA finds a low-dimensional linear subspace that maximizes variance
Data preprocessing
- $X \leftarrow X - \mu$
- centering the data
- assuming zero-mean data
Covariance Matrix
\[\Sigma = \frac{1}{n} X^\top X\]- measures correlations between features
- variance along a direction $u$: $u^\top \Sigma u$
Optimization
- first principal component solves:
- maximize projected variance, unit-norm constraint avoids trivial solutions
- solution: eigenvector of $\Sigma$ with the largest eigenvalue
- in practice, using SVD of the data matrix for numerical stability
- keep top-$k$ principal components; discard components with small eigenvalues (often noise)
Limitations
- sensitive to feature scaling
- cannot capture nonlinear manifolds