AudioToken: Adaptation of Text-Conditioned Diffusion Models for Audio-to-Image Generation
Overview
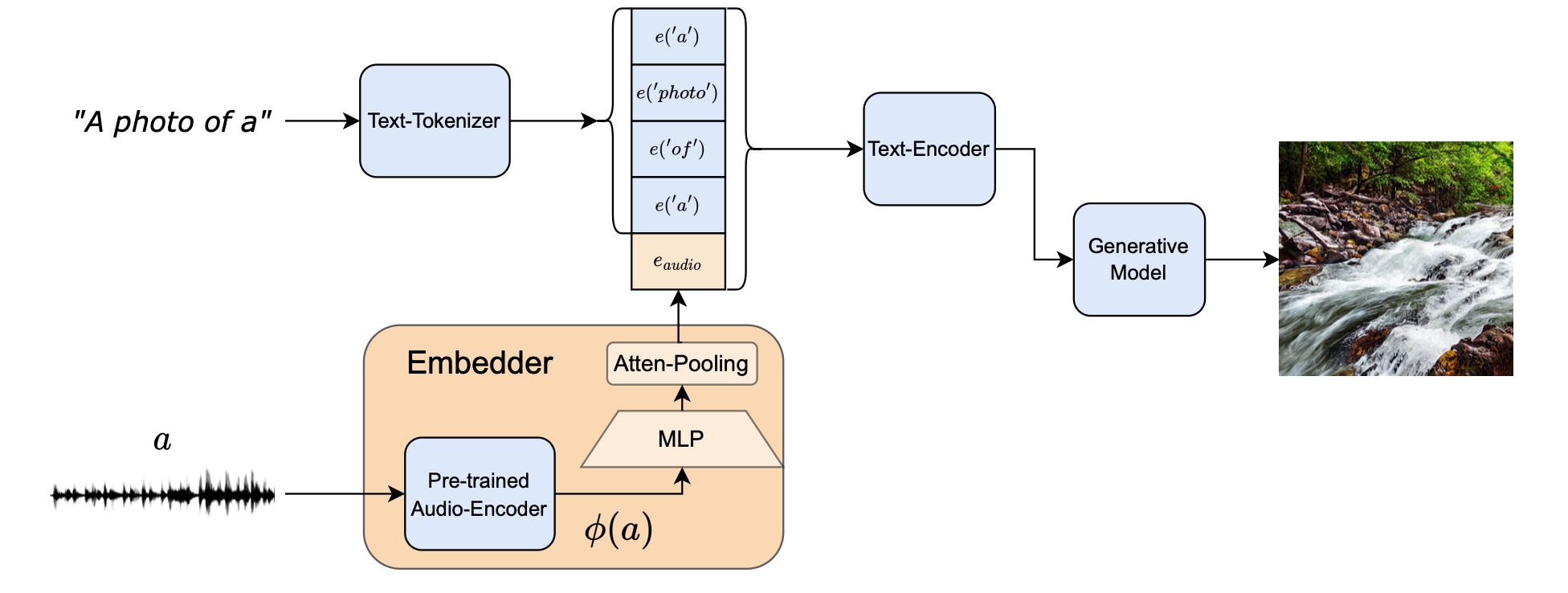
- Pre-trained text-to-image generation model (Stable Diffusion)
- Pre-trained audio-encoder (BEATs)
- MLP + Attentive Pooling 학습시킴 (by conditional diffusion loss + classification loss)
Contribution
- Pre-trained text-conditioned generative model을 이용해서 audio-based conditioning 구현
- 이를 위한 새로운 evaluation framework 제시
- Audio-Image Similarity, Image-Image Similarity, Audio-Image Content
Method
-
‘BEATs’라는 pre-trained audio classification network를 사용
- Earlier layers(4, 8, 12번째 레이어)와 last hidden layer를 concatenation → temporal audio embedding으로 사용
-
이를 textual embedding space로 projection 하는 MLP와 attentive pooling layer 학습시켜 통과되어 나온 audio embedding을 ‘a photo of a’ token들 뒤에다가 붙임
-
두 개의 Linear layer + GELU non-linear activation function
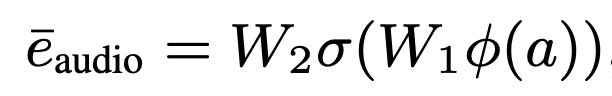

-
-
해당 text를 text-encoder로 CLIP embedding 생성 후 이를 T2I model의 cross-attention layer에 injection
-
Training은 일반적인 Conditioned diffusion model의 loss + Classification loss
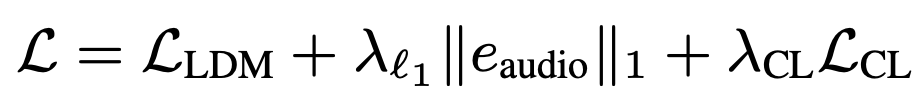
-
일반적인 Diffusion Model에서의 Loss (𝜏는 conditioning을 위한 encoder)
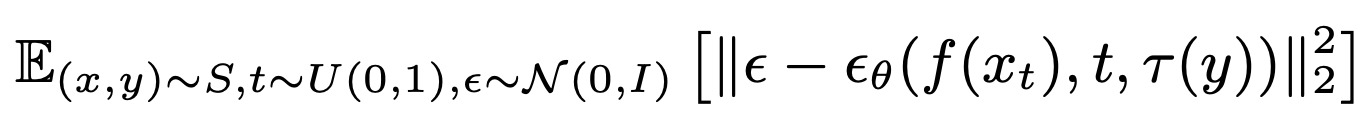
-
audio embedding과 데이터의 label의 유사도가 높아지도록 하는 loss
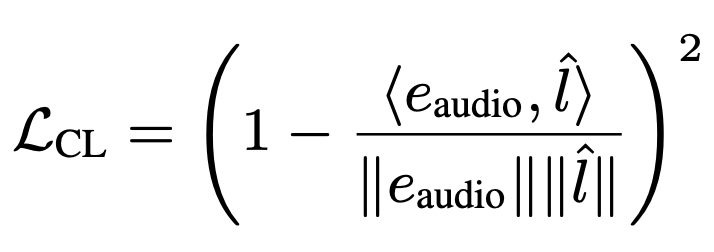
-
Pre-trained 모델들은 frozen 시키고 새롭게 추가한 layer들만 학습시킴
-
Evaluation
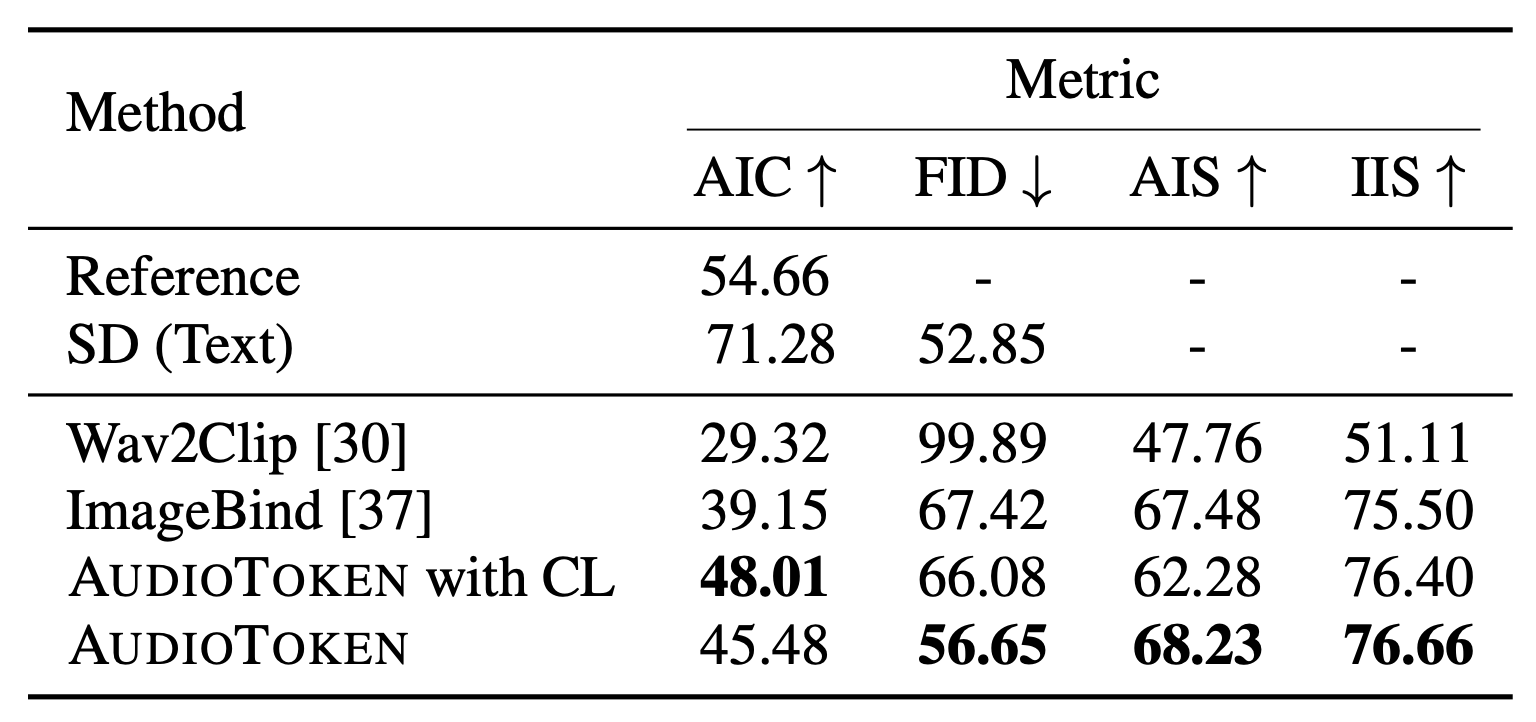
- Audio-Image Similarity
- Wav2CLIP 모델 사용
- Audio-Image 간의 유사도 측정 가능
- Wav2CLIP 모델 사용
- Image-Image Similarity
- 생성된 이미지와 ground truth 이미지 간의 CLIP score 비교
- Audio-Image Content
- Image classifier에서 예측된 class와 ground truth audio label 간의 additional CLIP-based score 사용
- Human Evaluation
- 일반적인 유저 평가
- 생성된 이미지가 label과 관련이 있는지 1에서 5점 사이로 평가
Result

- 위에서 아래로 Wav2Clip, Image-Bind, AudioToken, 그리고 Ground Truth
Details
- Pre-trained text-to-image diffusion model(e.g. stable diffusion)과 pre-trained audio-encoder를 사용해서 input audio signal에 잘 부합하는 이미지를 생성하자
- 왜 audio를 text로 mapping하는 pre-trained encoder + auxiliary neural network(MLP)를 사용해서 굳이 audio signal을 text space 위로 projection 시키는가?
- Pre-trained text-to-image generation model 사용하기 위해
- “not learn a new generative model with audio-visual pairs”
- 보통 CLIP을 가지고 사용한 모델이 많은데, 별도의 학습 없이 이를 사용하려면 audio를 text embedding으로 잘 mapping 시키는 것이 필요
- 논문에서 제시한 핵심은 성능이 좋은 text-to-image generation model을 잘 leverage 하자는 것.
- Pre-trained text-to-image generation model 사용하기 위해
- 왜 audio를 text로 mapping하는 pre-trained encoder + auxiliary neural network(MLP)를 사용해서 굳이 audio signal을 text space 위로 projection 시키는가?
Takeaway Message
- Audio input에 관해 너무 단순한 이미지만 생성하지 않을까?
- ‘개가 짖는 소리’ → ‘개 이미지’
- 논문의 figure를 보면 정말 복잡한 이미지를 생성하는지에 관해 의문
- Figure 수도 그렇게 많지 않다.
- Audio-to-text encoder의 성능에 sensitive 할 것 같다.
- Stable Diffusion(SD)등 text-to-image 모델을 사용해서 audio-to-image task를 해결하려는 시도는 좋으나, 그러면 text-to-image 생성 성능은 오로지 stable diffusion에 bounded 되므로 chicken neck problem이지 않을까 싶다.
- 그리고 pre-trained audio encoder를 textual embedding space에 mapping하기 위해 추가적인 MLP 학습 → 완전한 training-free 방식이 아니다.
- Audio에 관한 spatial information도 같이 반영하면 어떨까?
- Stereo로 녹음된 음원에 관해 음원이 들려오는 방향에 따라 이미지에서 생성되는 객체의 위치를 조절하는 것.
- 개인적으로 연구 중인 Stable Diffusion에서 원하는 크기와 위치로 각 객체를 positioning 하도록 생성하는 guidance in diffusion model을 녹여낼 수 있을 듯.
- 원하는 크기와 위치에 객체를 생성하도록 유도하는 논문은 꽤 있다. → 이를 audio와 결합하려는 시도는 어떨지가 개인적인 의견.
- e.g. 왼쪽에서 주로 개구리 소리가 들리면 이미지에서도 왼쪽 영역에 개구리를 생성하는 것.
- Object를 guidance 하는 것은 어렵지 않으나, 각 방향에서 들려오는 소리가 어떠한 객체에 해당되는 소리인지를 구하는 게 어려울 것 같다.
- Text에서 subject token을 뽑고, 이를 각 방향의 소리와 Hungarian algorithm으로 matching 시키는 방법은?
- Subject token과 주요한 audio signal을 잘 matching 하는 게 난관이 될 듯.
- 이동하는 소리(e.g. 왼쪽에서 오른쪽으로 차 소리가 이동)에 관해서는 어떻게 이미지로 생성해야할지 의문
- Stereo로 녹음된 음원에 관해 음원이 들려오는 방향에 따라 이미지에서 생성되는 객체의 위치를 조절하는 것.
- T2I model을 fine-tuning 시키는 방법들이 많이 나왔는데 (e.g. ControlNet, GLIGEN 등) 이러한 모델들을 이용하면 어떨까?
- Training 자체가 cost가 크다.
- 문제는 audio에서 grounding token을 뽑아내는 것.
Reference
- Guy Yariv et. al., “AudioToken: Adaptation of Text-Conditioned Diffusion Models for Audio-to-Image Generation”, arXiv:2305.13050 (2023)