Object-Centric Learning with Slot Attention
Abstract
- 대부분의 deep learning 접근법은 natural scenes의 compositional properties를 파악하지 못하는 distributed representations를 학습한다.
- 본 논문에서는 Slot Attention module을 소개하는데, 이 모듈은 perceptual representations (e.g. CNN의 output)과 “slot“이라는 task-dependent abstract representations 사이의 인터페이스 역할을 한다.
- Slot은 iterative attention을 통해 입력의 어떠한 object에도 binding할 수 있다. 이는 여러 attention rounds의 competitive procedure를 통해 specialize 된다.
- Slot Attention을 사용하면 unsupervised object discovery 또는 supervised property prediction tasks에 대한 학습에서도 unseen composition에 대해 일반화 할 수 있는 object-centric representations를 추출할 수 있다.
Introduction
Object-centric Representation 획득의 어려움
- Raw perceptual input (e.g. 이미지 또는 비디오)에서 object-centric representation을 얻는 것은 challenging하다.
- 대부분 supervision이 필요하거나, 특정한 architecture (e.g. Capsule Networks)를 사용하는 것을 필요로 한다.
Slot Attention의 제안
- 이 논문에서는 Slot Attention module을 제안한다. 이는 perceptual representations (e.g. CNN의 output)과 “slot“이라는 변수들 사이의 differentiable interface이다.
- Capsule Networks의 capsules와 달리, slot은 특정한 object type 또는 class에 특화되지 않는다. 대신, “object files”와 유사하게 작동하여, 각 slot이 입력의 어떠한 object에도 bind 할 수 있는 공통의 representational format을 사용한다.
- Slot Attention은 architectural component로 쉽게 구현될 수 있으며, 다양한 downstream tasks에 end-to-end로 학습될 수 있다. 이 논문에서는 image reconstruction과 set prediction을 downstream task의 예시로 사용한다.
Main Contribution
- Slot Attention module의 도입
- Perceptual representations와 set-structured representations 사이의 인터페이스 역할을 한다.
- Unsupervised object discovery를 위한 Slot Attention-based architecture의 적용
- 이 접근법은 memory efficient하며 학습 속도가 빠르다.
- Slot Attention이 supervised object property prediction에 적용될 수 있음을 보여준다.
- Attention mechanism이 object segmentation에 대한 직접적인 supervision 없이 개별 object를 강조할 수 있다는 것을 보여준다.
Method
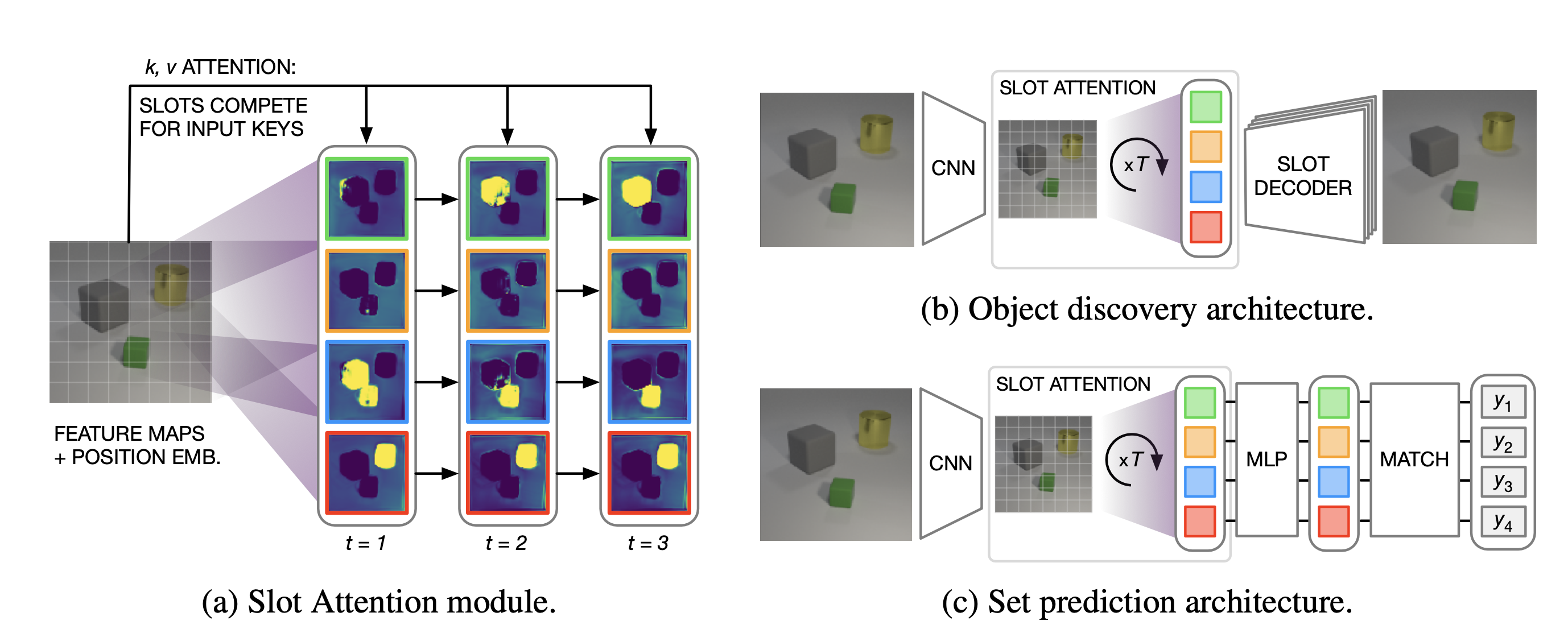
Slot Attention Module
- $N$개의 input feature vectors set을 $K$개의 output vectors set으로 mapping 하는 모듈
- 여기서 $K$개의 output vectors set을 slot이라고 한다.

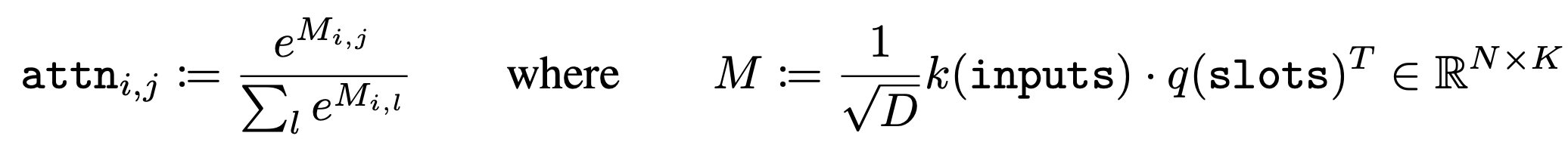
Attention mechanism에서 query와 key를 dot product 해서 차원 $D$로 정규화하고, 이를 softmax 취하는 것과 동일하다.
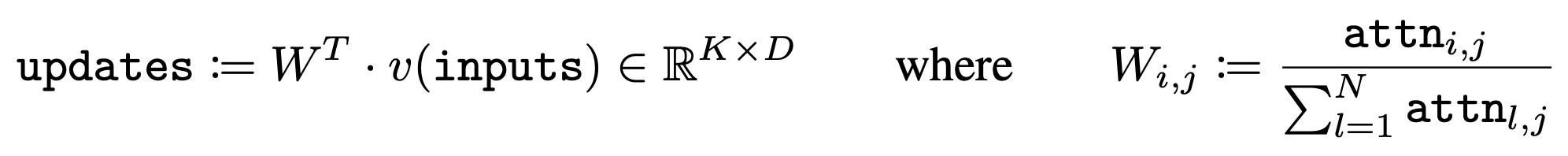
앞서 구한 attention weight을 가지고 value와 곱해서 GRU의 input으로 넣어 slot representation을 업데이트 하는 과정이다.
- Iterative attention mechanism
- Common distribution에서 random하게 샘플링되어 초기화디고, $t$가 1부터 $T$일 때까지 반복적으로 refinement 된다.
- 매 iteration에 slot들은 softmax-based attention mechanism에 의해 경쟁하고, GRU와 같은 recurrent update function을 사용하여 representation을 업데이트 한다.
- 이전 iteration에 학습한 slot representation도 반영하겠다는 의도로 보여진다.
- Final representation을 가지고 downstream task에 적용할 수 있다.
- 일반적으로 잘 알고 있는 transformer와 차이가 크지 않다.
- Learnable linear transformation $k$, $q$, 그리고 $v$를 사용
- Slot들에 관해 attention coefficient가 normalization 되며, 이 부분이 slot들이 서로 경쟁할 수 있도록 유도한다.
- Weighted sum 대신 slot 수에 관해 weighted mean을 사용해서 가변적인 개수의 slot에 관해 normalization 될 수 있도록 한다.
- 이 부분이 slot들이 서로 input의 다른 부분에 binding 되도록 경쟁을 유도하는 핵심 요소 중 하나라고 이해했다.
- Slot Attention은 permutation invariance와 permutation equivariance를 특징으로 지닌다.
- Permutation invariance: input이 어떠한 순서로 오든 간에 slot attention의 output에는 영향을 끼치지 않는다.
- Permutation equivariance: slot을 initialization 한 이후에 순서를 바꾸는 건 module의 output인 slot의 순서를 바꾸는 것과 동일하다.
Comment
Slot attention mechanism 그 자체가 objective가 존재하는 건 아니지만, 최종적인 모델의 loss를 줄이는 방향으로 backpropagation 등 어떠한 update rule에 의해 학습이 된다는 점을 유의한다. 마치 transformer의 attention mechanism에서도 attention을 위한 별도의 objective가 존재하지 않았고, 대신 그러한 mechanism을 downstream task에 적용할 수 있었다는 것과 같은 맥락이다.
Object Discovery
Encoder
- Slot Attention은 input representation을 vectors set으로 변환하므로 autoencoder architecture의 encoder 부분에 사용할 수 있다.
- Slot이 hidden representation이 되므로 representational bottleneck으로 볼 수 있다.
- 구성 요소
- Positional embedding이 추가된 CNN backbone
- Slot Attention module
- Output
- Scene 정보를 grouping 한 표현을 지니는 slot의 집합
Decoder
- Slot decoding
- 각 slot은 spatial broadcast decoder를 사용하여 개별적으로 decoding 된다. (similar to IODINE)
- Slot representation
- Slot 마다 2D grid로 broadcast 되고 positional embedding이 더해진다.
- CNN decoding
- 각 grid는 slot 간의 공유되는 파라미터를 지닌 CNN을 사용하여 decoding 된다.
- 이미지의 너비와 높이인 $W \times H \times 4$ 크기의 출력을 생성한다.
- Output 채널은 RGB 색상 채널과 (정규화되지 않은) alpha mask를 encoding한다.
- Alpha mask 정규화
- Slot 간의 alpha mask를 softmax를 사용하여 정규화
- 이를 mixture weight으로 사용하여 individual reconstruction을 하나의 single 이미지로 결합한다.
Set Prediction
- Set representation은 다양한 data modality에서 사용된다.
- point cloud 예측, 이미지 내 여러 객체 분류, 원하는 특성을 가진 분자 생성 등의 작업에 활용
- 본 논문에서 고려하는 예시에서는 입력 이미지와 각각의 객체를 설명하는 prediction target set이 주어진다.
- Set prediction에서의 challenge
- $K$ 요소의 집합에 대해 $K!$ 개의 가능한 equivalent 표현이 있다는 것 (target의 order는 임의적이므로)
- Slot Attention의 출력 순서는 무작위이며 입력 순서와 독립적이다.
- Slot Attention은 input scene의 distributed representation을 각 객체가 포함된 set representation으로 변환하는 데 사용 가능하다.
Comment
Slot Attention은 set prediction에서 중요한 역할을 한다. 주어진 입력 이미지와 관련된 객체의 특성을 예측하는 것은 순서가 중요하지 않은 집합의 특성을 가지는데, Slot Attention은 이러한 순서에 독립적인 특성을 가진 set representation을 생성하는 데 도움을 준다.
Related Work
- Slot Attention에서 input에서 slot으로 mapping 되는 attention-based assignment에서는 기존처럼 오직 input에 관해서만 normalization 되는 것이 아니라 slot들에 관해 normalization 되는데, 이는 slot들이 input에 관해 clustering을 수행하도록 경쟁하게 만든다.
- 단지 temporal data만 고려하지 않고, recurrent update function을 사용해서 단일 input에 관해 반복적으로 refinement 할 수 있도록 한다.
- 본 논문에서 소개한 방법은 soft k-means clustering과 연관되어 있다.
- Soft k-means clustering과의 공통점
- Slots = cluster centroids
- Soft k-means clustering과의 차이점
- Learnable parameter를 통한 linear projection을 사용
- Dot product similarity 계산
- Learnable 하면서 cluster-specific parameter를 사용하는 방법들도 존재하지만, 본 논문의 방법은 recurrent, multi-step update를 사용하면서 permutation symmetry를 보장한다는 점이 다르다.
- Soft k-means clustering과의 공통점
Experiments
Datasets
- CLEVR
- Object discovery와 set prediction에 사용
- Object discovery
- 처음 70K의 sample들을 가져와서 학습에 사용
- 320개의 test example을 evaluation으로 사용
- Set prediction
- Training-validation split = 70K and 15K images
- Object discovery
- CLEVR6: 한 scene에 최대 6개의 object를 포함 (slot 수는 7개)
- CLEVR10: 한 scene에 최대 10개의 object를 포함 (slot 수는 11개)
- Object discovery와 set prediction에 사용
- Multi-dSprites and Tetrominoes
- Object discovery에만 사용
- 처음 60K의 sample들을 가져와서 학습에 사용
- 320개의 test example을 evaluation으로 사용
- Object discovery에만 사용
Object Discovery

위의 표를 참고하면, Slot Attention이 IODINE, MONet, Slot MLP(Attention mechanism이 아니라 단순히 MLP로 input에서 slot으로 mapping 하는 네트워크 구현)보다 모든 dataset에서 가장 좋은 결과를 보였다.
또한 오른쪽 그래프에서 inference에서 iteration을 더 많이 할수록 ARI가 높아진다는 사실을 보였다.
여기서 사용한 지표는 ARI(Adjusted Rand Index)이다.
Rand Index(RI)
\[\frac{a + d}{a + b + c + d}\]- 실제 데이터 포인트들의 grouping과 측정하고자 하는 clustering algorithm(여기서는 slot attention)에 의해 grouping 된 결과가 얼마나 유사한지를 측정하는 지표
- Preposition: Same label에 속하는 data point는 같은 cluster에, different label에 속하는 data point는 다른 cluster에 할당되어야 한다.
- Contingency table(4개의 entry로 구성)
- $a$: same label → same cluster
- $b$: different label → same cluster
- $c$: same label → different cluster
- $d$: different label → different cluster
- Limitation: random assignment에도 영향을 받는다.
Adjusted Rand Index(ARI)
\[\text{ARI} = \frac{\text{RI} - \text{Expected RI}}{\max \text{RI} - \text{Expected RI}}\]- Expected RI: random assignment로 나오는 평균적인 RI
- ARI → 1: strong assignment
- ARI → -1: worse than random assignment
- ARI → 0: close to random assignment
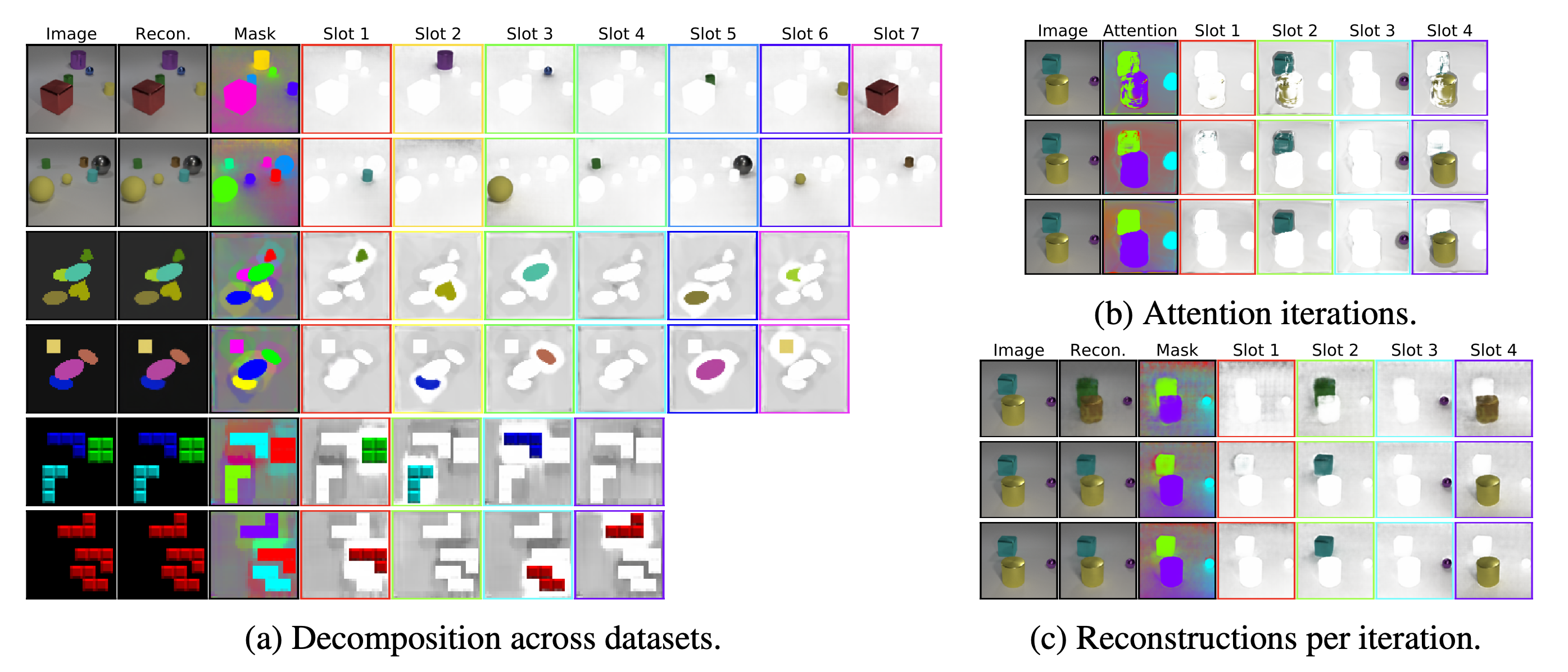
- (a)는 각 slot의 representation이 독립적인 object에 잘 binding 되었음을 시각적으로 보여준다.
- (b)는 Slot Attention에서 iteration 수가 늘어날수록 해당 object에 slot의 binding이 더 정교해짐을 attention 결과를 통해 알려준다.
- Decoder가 반드시 있지 않아도 Slot Attention의 결과만으로 충분히 object discovery 결과를 얻을 수 있음을 내포한다.
- (c)는 각 iteration에서 바로 reconstruction을 수행했을 때 나오는 결과를 보이며, 마찬가지로 iteration이 증가할수록 reconstruction의 품질이 올라감을 확인할 수 있다.
- Slot 수가 object 수보다 많으면 object에 대응되지 않는 나머지 slot은 background에 대응된다.
- 위의 그림에서 red border에 보여지는 결과가 바로 background

Gray scale 이미지에 관해서도 unsupervised object discovery가 잘 수행됨을 확인할 수 있다.
Set Prediction
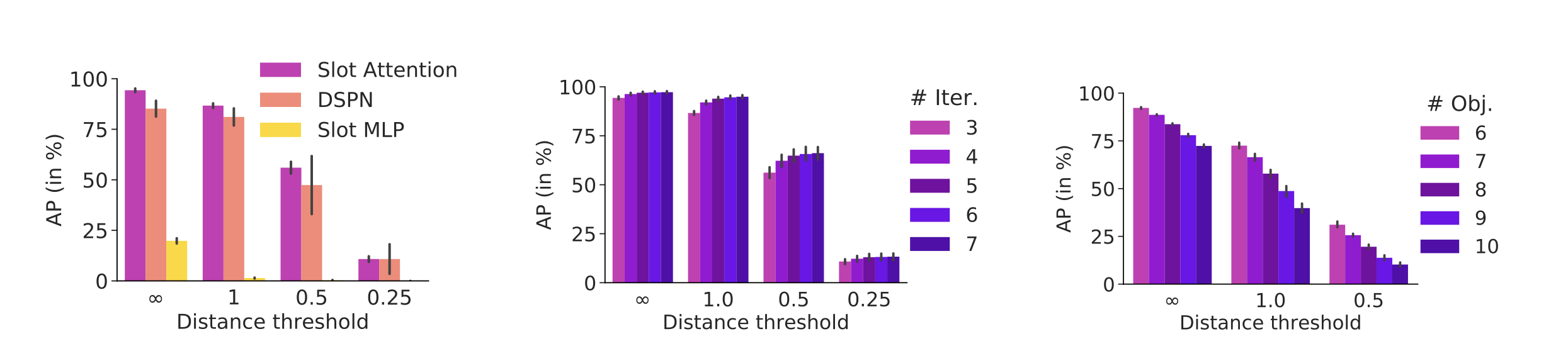
위의 그래프는 Slot Attention을 사용했을 때의 예측된 set의 존재 확률과 위치가 실제 set에 얼마나 잘 부합하는지를 보인 실험 결과이다. 여기서 “distance threshold”는 set의 예측 위치와 실제 위치 간의 허용 가능한 거리를 나타내는데, set의 예측 위치가 실제 위치에서 threshold 안에 있으면 해당 예측을 올바른 것으로 간주하여 additional indicator score를 AP에 반영하고, 그렇지 않으면 0으로 한다. “Distance threshold”가 무한대면 그러한 set의 위치가 정확하지 않아도 additional indicator score로 예측한 존재 확률에 관해 바로 AP에 적용한다고 해석할 수 있다.
전반적으로 Slot Attention을 사용했을 때 AP가 높고, iteration이 증가할수록 정확도가 올라감을 확인할 수 있다. 그러나 object 수가 많아질수록 정확도가 감소한다는 점을 볼 수 있다.

위는 실제 set prediction 결과를 visualization 한 그림이다.
Take-away Message
- Slot들이 배타적으로 경쟁하면서 input으로 주어지는 representation을 aggregate 해서 좀 더 object-centric representation을 만들고자 하는 게 이 논문에서 중요한 철학으로 해석된다.
- 이 논문에서 나온 Slot Attention에 주목하는 이유는, 최근에 다양한 논문에서 Slot Attention을 사용하여 문제를 해결하는 경우가 늘고 있어서다.
- Improving Cross-Modal Retrieval with Set of Diverse Embeddings
- 이미지의 local representation과 text 간의 ambiguous mapping을 극복하기 위해 slot attention으로 exclusively aggregate 하는 방법 (∵ 한 object는 다양한 text prompt에 일대다로 대응될 수 있으므로)
- Object-Centric Slot Diffusion
- Stable Diffusion이 취약한 compoisitional text-to-image generation에서 slot representation을 inference 과정에서 U-net에 주입하는 방법
- Improving Cross-Modal Retrieval with Set of Diverse Embeddings
- Stable Diffusion으로 cross-attention manipulation으로 각 subject token에 관한 guidance를 부여했음에도 불구하고 multi-labeled objects를 잘 생성하지 못한 경우의 self-attention map을 살펴보면 특정 token의 cross-attention이 주목해야 할 부분에 self-attention의 cluster가 형성되어 있지 않음을 확인했다.
- 다시 말해, cross-attention과 self-attention을 서로 조화시켜야 한다.
- 그러면 diffusion model의 inference의 초기 단계에서 빠르게 self-attention에 생성하기를 원하는 object에 대한 clustering이 이루어져야 할 것이다.
- Grounded Text-to-Image Synthesis with Attention Refocusing
- Compositional Text-to-Image Synthesis with Attention Map Control of Diffusion Models
- 이에 관해 유사한 아이디어를 가지고 접근한 논문이 있다. Slot Attention은 사용하지 않았지만, object마다 생성해야 할 영역을 BoxNet이라는 학습된 모델을 통해 bounding box로 예측하고 cross-attention을 해당 영역에 집중하게 한다. 이러한 아이디어는 그동안 적지 않은 논문들이 제시한 바이다.
- 생성해야 할 영역에 self-attention이 cluster를 형성하도록 $q$와 $k$를 곱했을 때 나오는 similarity에 관해 해당 영역 외의 나머지 similairity는 0으로 만들어 버림으로써 해당 영역 안쪽에만 유사한 token으로 clustering 되도록 하고 있다.
- BoxNet을 training 시켜야 하는 단점이 있고, 과연 bounding box로 예측을 하는 것이 정말 바람직한 건지는 의문이다.
- Bounding box가 실제 객체의 geometry에 정확하게 들어맞지 않을 것이다. (저자도 직접 논문에서 언급했고, 논문의 첨부 예시 샘플을 자세히 보면 self-attention control을 적용했을 때 오히려 더 부자연스러운 모습이 확인된다.)
- 별도의 모델을 두어서 bounding box로 예측하는 것보다는 최대한 inference 과정에서 activation을 잘 leverage 하는 방법은 없을까 고민하고 있다.
- 진정한 unsupervised 또는 self-supervised method로 clustering을 형성하는 방법을 찾는 것이 관건이 될 것이고, 그 해답이 Slot Attention에 있지 않을까는 생각이다.
Reference
- Francesco Locatello et. al., “Object-Centric Learning with Slot Attention.” arXiv:200615055 (2020)