Preliminaries
Denoising Diffusion Implicit Model

DDIM은 기존의 DDPM의 forward process에서 Markovian 방법론을 택한 대신에 그 직전의 이전의 샘플링도 evidence로 고려하는 non-Markovian 방법론을 택했다. 이를 바탕으로 denoising의 매 timestep 마다 샘플링하는 식을 다음과 같이 정리할 수 있는데, 이 식은 해당 timestep에서 예측한 $x_0$에 대한 항, $x_t$를 가리키는 방향, 그리고 random noise 항으로 구성되었다. 이때, $\sigma_t$가 0이면 forward process가 deterministic 해진다고 알려져 있다.
Stable Diffusion
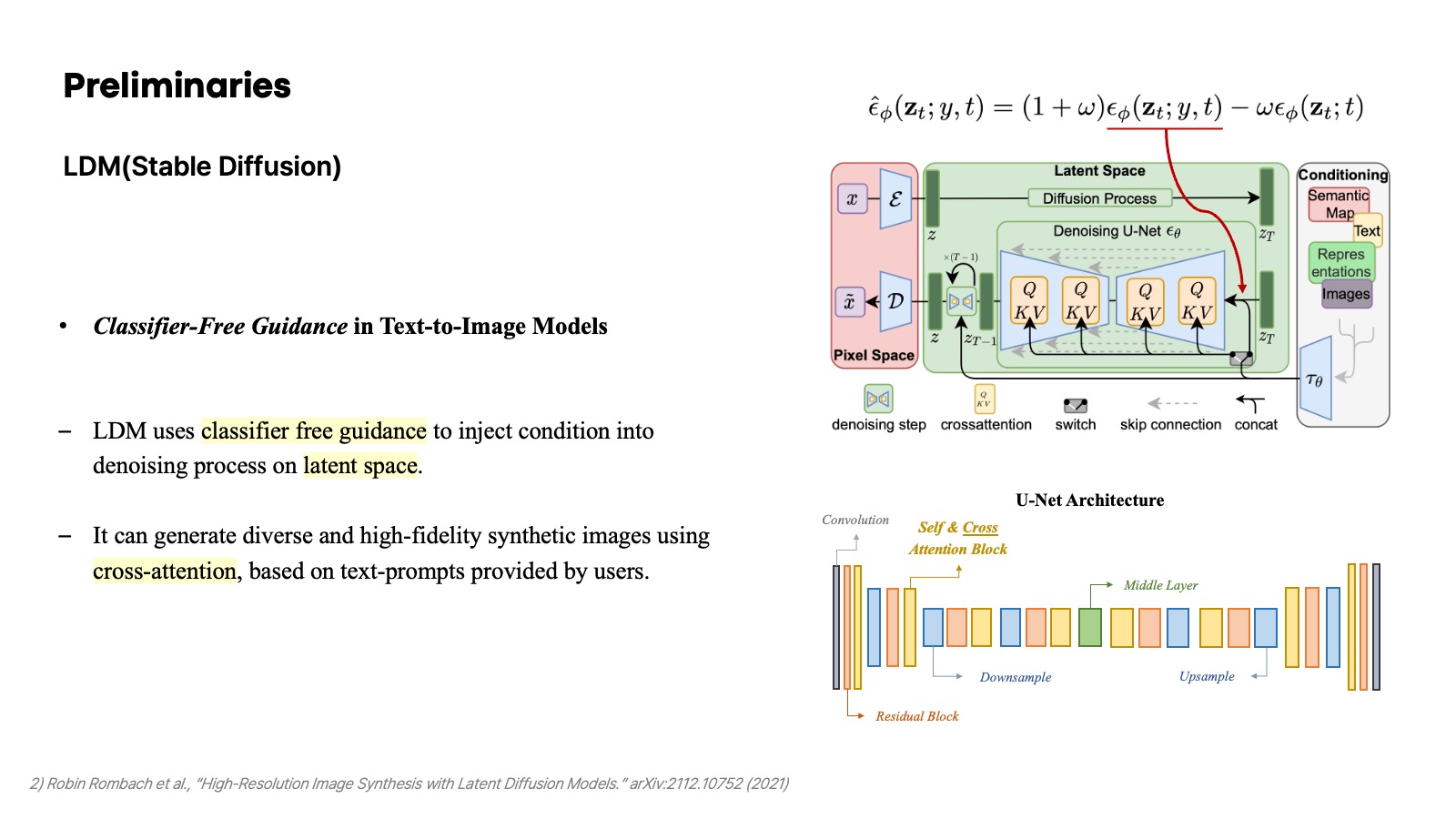
이미지 생성 모델로 잘 알려진 Stable Diffusion은 Latent Diffusion Model을 바탕으로 한다. 핵심을 요약하자면, 이전의 diffusion 모델처럼 이미지 또는 이미지 차원 자체를 가지고 backward와 forward process를 수행하지 않고 latent space 상에서 noise를 추가하거나 denoising 하는 과정을 수행한다. 또한 이전의 classifier-guidance에서 직접적인 classifer를 사용하는 것과 달리 conditioning이 주어졌을 때와 그렇지 않은 경우 두 가지를 모두 수행하는 classifier-free guidance를 통해 conditional generation을 수행할 수 있다는 점이 특징이라고 볼 수 있다. 이때, conditioning에서 cross-attention mechanism을 사용한다는 것이 주목할 만한 부분이고, 이미지를 생성할 때 주어지는 condition이 어떠한 부분에 좀 더 집중해야 하는지를 조작할 때 이 cross-attention map을 다루는 경우가 많다.
Attributes in Generation & Editing

이미지를 생성하는 데 있어서 중요한 속성들은 크게 이처럼 구분할 수 있다. 생성하려는 객체가 어떠한 방향으로 바라보게끔 하는지에 관한 속성을 여기서는 viewing direction으로 부르겠다. 그런데 stable diffusion의 latent space 상에서 viewing direction을 바꿀 수 있는 editing direction을 찾는 건 쉽지 않은 것으로 보인다. 아마 개인적으로 DragGAN 또는 DragDiffusion에 이를 위한 단서가 있지 않을까 생각하고 있다.
Shape, position, appearance를 조절하는 방법들은 지금까지 많은 논문들이 제안해 왔다. 다양한 방법들이 존재하지만, 특히 feature map, attention map, prediction 등 이와 관련한 어떠한 energy function 또는 loss function을 정의해서 gradient를 구하고 해당 방향으로 이를 shift 시키는 방법들이 적지 않다. 그래서 필자가 생각한 방법도 어떠한 새로운 loss function을 정의해서 이를 줄이는 방향으로 prediction을 shift 시키는 쪽으로 접근하는 것이다.
Guidance in Diffusion Sampling Process
Asymmetric Reverse Process
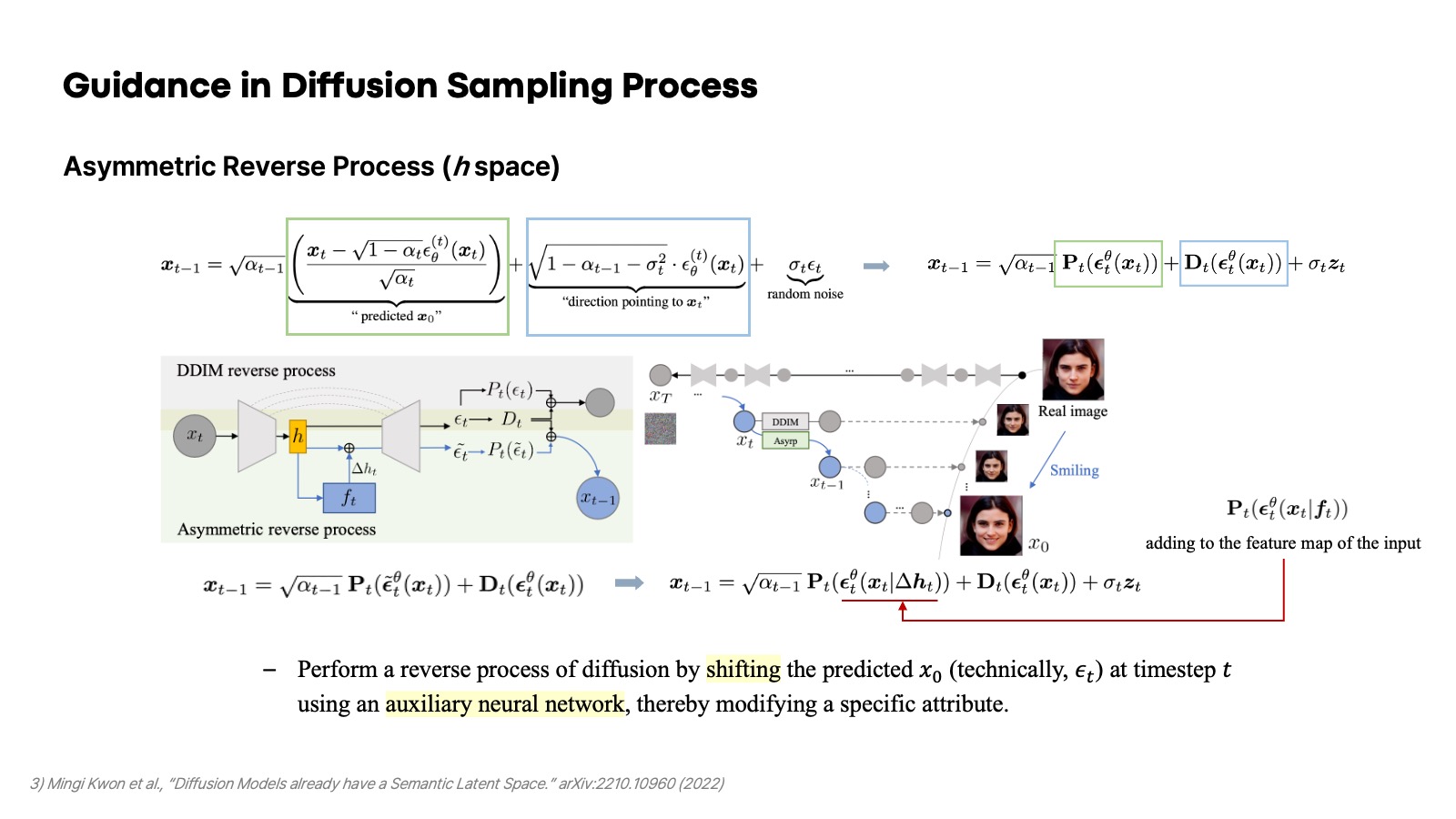
Asyrp 또는 h-space라고 불리는 Asymmetric Reverse Process는 이 연구 주제에서 유명한 논문 중 하나이다. 앞서 서술했다시피 DDIM의 sampling 식을 분석해 보면 해당 timestep에서 예측하는 $x_0$에 대한 항이 있다. Asyrp에서는 추가적인 auxiliary 모델을 사용해서 이 $x_0$를 어떠한 하나의 속성에 관해 원하는 방향으로 shift 시키는 방법을 보여줬다. Pre-trained Unet 모델에 어떠한 하나의 속성을 shift 시키는 CNN을 추가해서 Unet이 noise를 예측할 때 해당 noise가 shift된 결과를 낼 수 있도록 하는 것이다.
Diffusion-based Image Translation
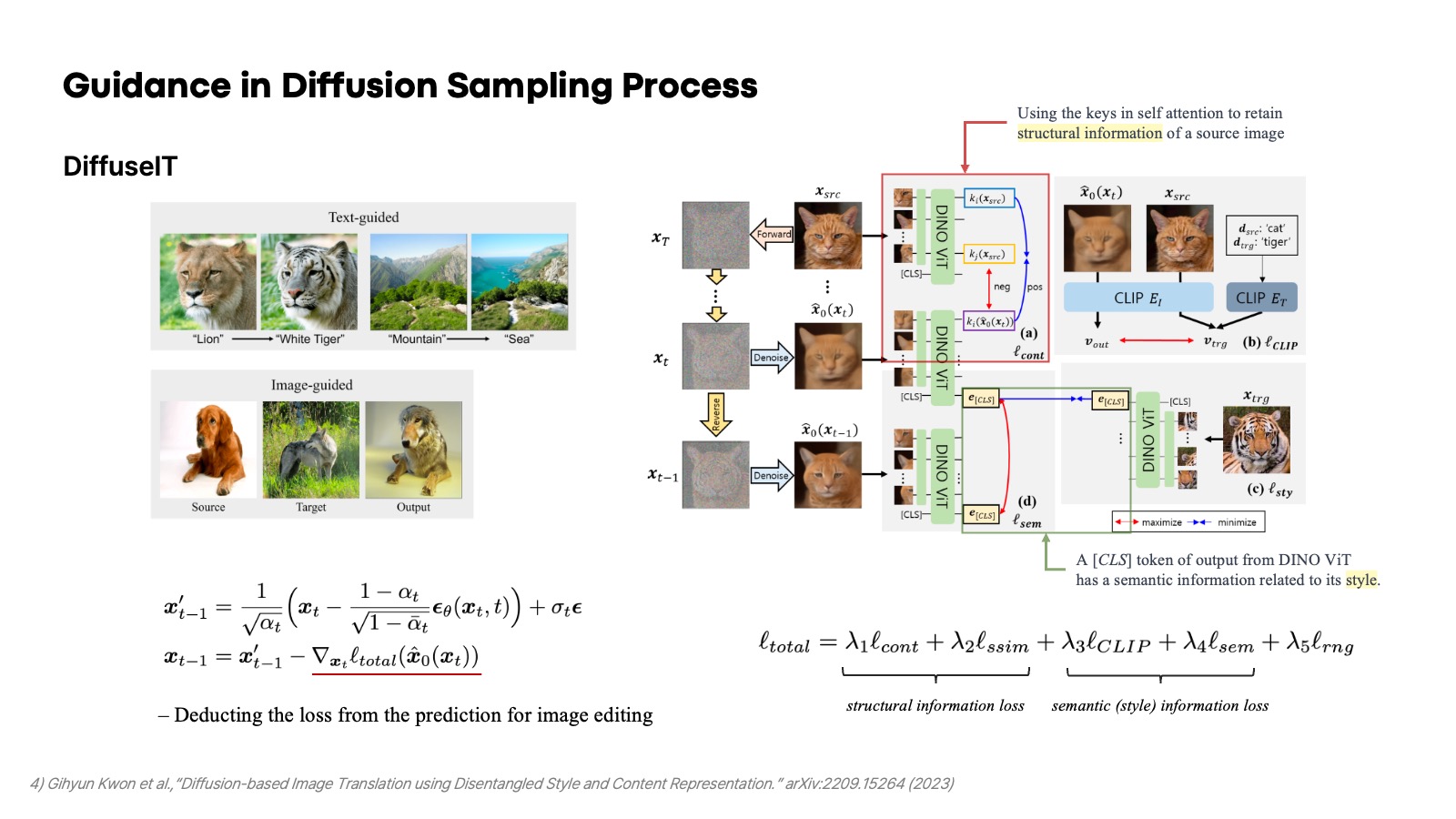
DiffuseIT(Diffusion-based Image Translation)으로 불리는 이 논문은 image editing에서 어떠한 text와 원하는 스타일을 담고 있는 이미지가 주어졌을 때, 생성한 이미지가 그 semantic 정보를 담을 수 있도록 매 timestep의 prediction을 DINO ViT의 input으로 사용해서 다음 sampling 결과를 shift 시킨다. 여기서 사용한 중요한 철학은 ViT에서 classification token은 이미지의 전반적인 semantic 정보를 담고 있고, ViT의 key 부분이 structure 정보를 갖고 있다는 것이다. 그래서 같은 위치에 있는 key는 유사해지게끔, 다른 위치에 있는 key는 멀어지게끔 하는 contrastive loss를 통해 구조적인 정보를 유지한다. 또한 매 timestep의 prediction을 ViT에 넣었을 때 나오는 classifcation token이 target으로 주어진 이미지에서 나온 classification token에 가까워지도록 하고, 그 이전 timestep에서 나온 classifcation token과는 멀어지게 contrastive loss를 사용함으로써 style 정보를 target에 맞는 방향으로 shift 시킨다. 그래서 source 이미지에 대하여 기존의 structure는 유지하면서 target 이미지와 text에 맞는 style을 가질 수 있도록 유도하는 방법이다.
Diffusion Self-Guidance
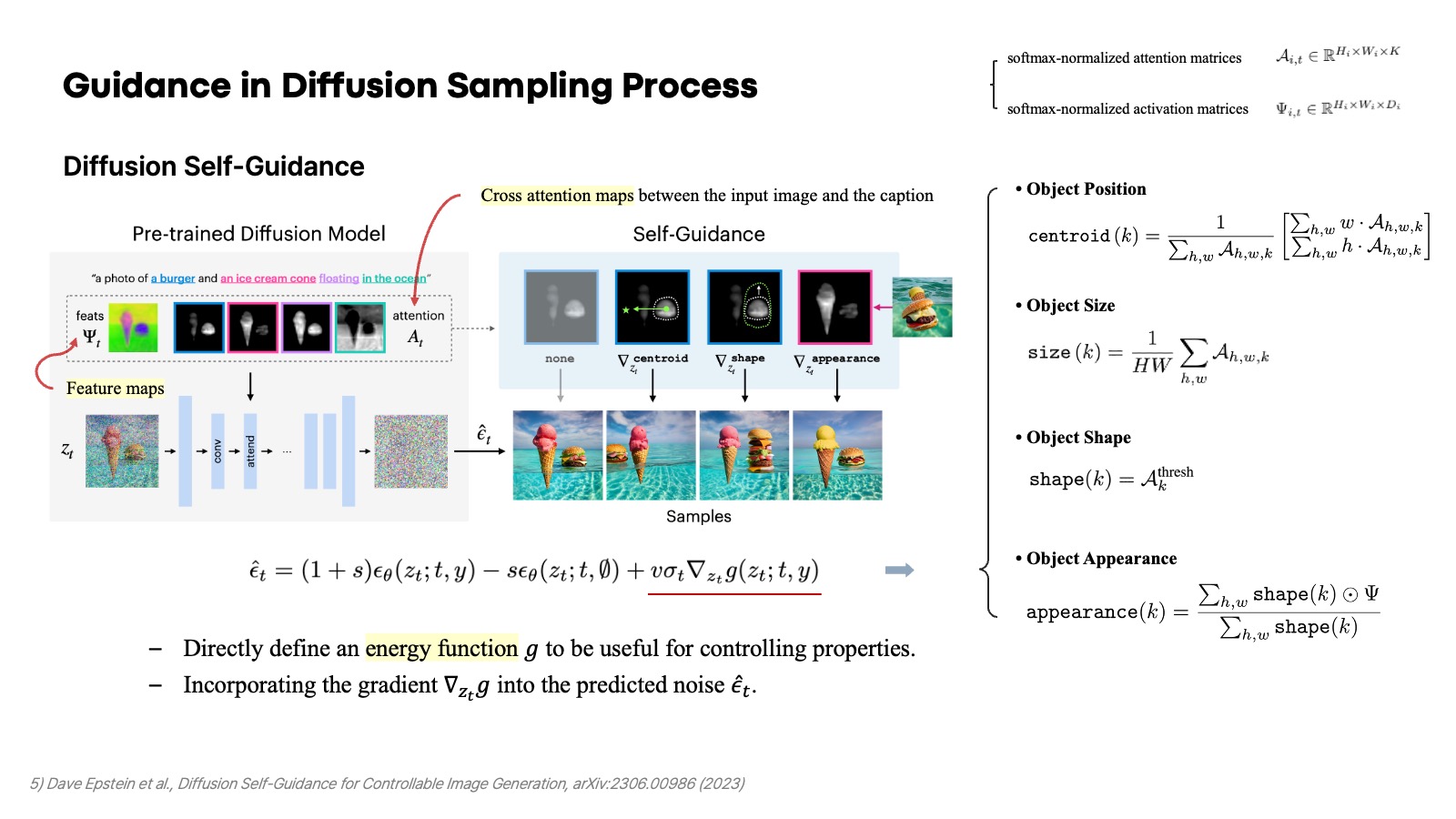
Diffusion Self-Guidance도 여러 energy function을 정의함으로써 주어진 이미지에서 어떤 특정 객체를 이동시키거나 크기를 늘리고, apperance도 바꿀 수 있는 editing 방법을 제안했다. Plug-and-Play에서 나온 것처럼 feature map 자체는 style 정보를 갖고 있다는 철학을 반영했고, token에 대한 객체의 기하학적인 정보는 그 token의 cross-attention map을 가지고 centroid, size, shape 등을 정의하여 energy function을 원하는 editing 경우에 맞게 적용할 수 있다고 주장한다. 여기서는 $z_t$에 대한 energy function의 gradient를 가지고 예측된 noise를 gradient ascent를 통해 shift 시키는 방식을 사용한다.

논문에서는 여러 예시를 들고 있지만, 여기서는 두 가지만 간단히 소개하고 넘어가겠다. 첫 번째는 기존의 위치와 크기를 유지하면서 새로운 apperance를 생성할 수 있는 energy function의 예시이다. 두 번쨰는 style 정보는 유지하면서 어떤 한 객체의 shape를 조절하는 예시이다. 이외의 더 자세한 예시는 논문을 참고하면 된다.
Pix2PixZero
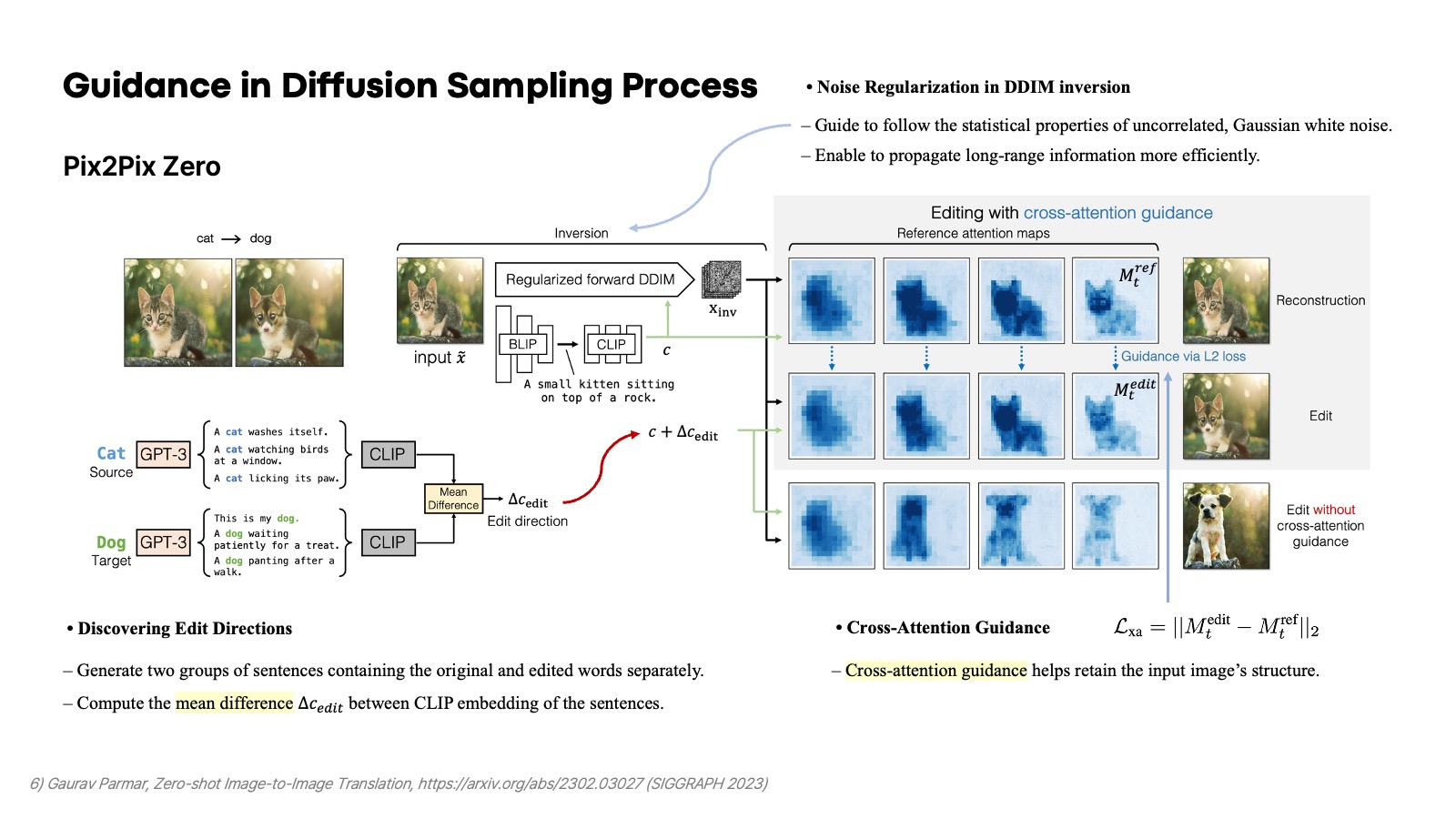
Pix2Pix Zero도 마찬가지로 기존의 이미지의 공간 정보는 유지하면서 원하는 대상으로 변화시킬 수 있는 방법을 제안했다. 그 구성 요소는 크게 두 가지이다. 첫 번째는 GPT-3를 가지고 생성한 CLIP embedding의 차이를 구해서 shift 시킨 context의 embedding을 conditioning으로 사용한다. 예를 들어, cat을 dog로 변경하고 싶으면 cat, dog에 관한 여러 문장을 GPT-3로 생성하고, 그 CLIP embedding의 평균의 차이를 shift 시키는 양으로 고려하여 이를 기존의 conditioning 문장에 더한다. 두 번째는 cross-attention guidance이다. 원래 대상을 Inversion 하고 다시 reconstruction 할 때 매 timestep에서 나오는 cross attention map을 aggregate 하고, 새로 shift 시킨 conditioning으로 이미지를 생성할 때 기존의 cross-attention map을 유지하도록 L2 loss를 사용한다.
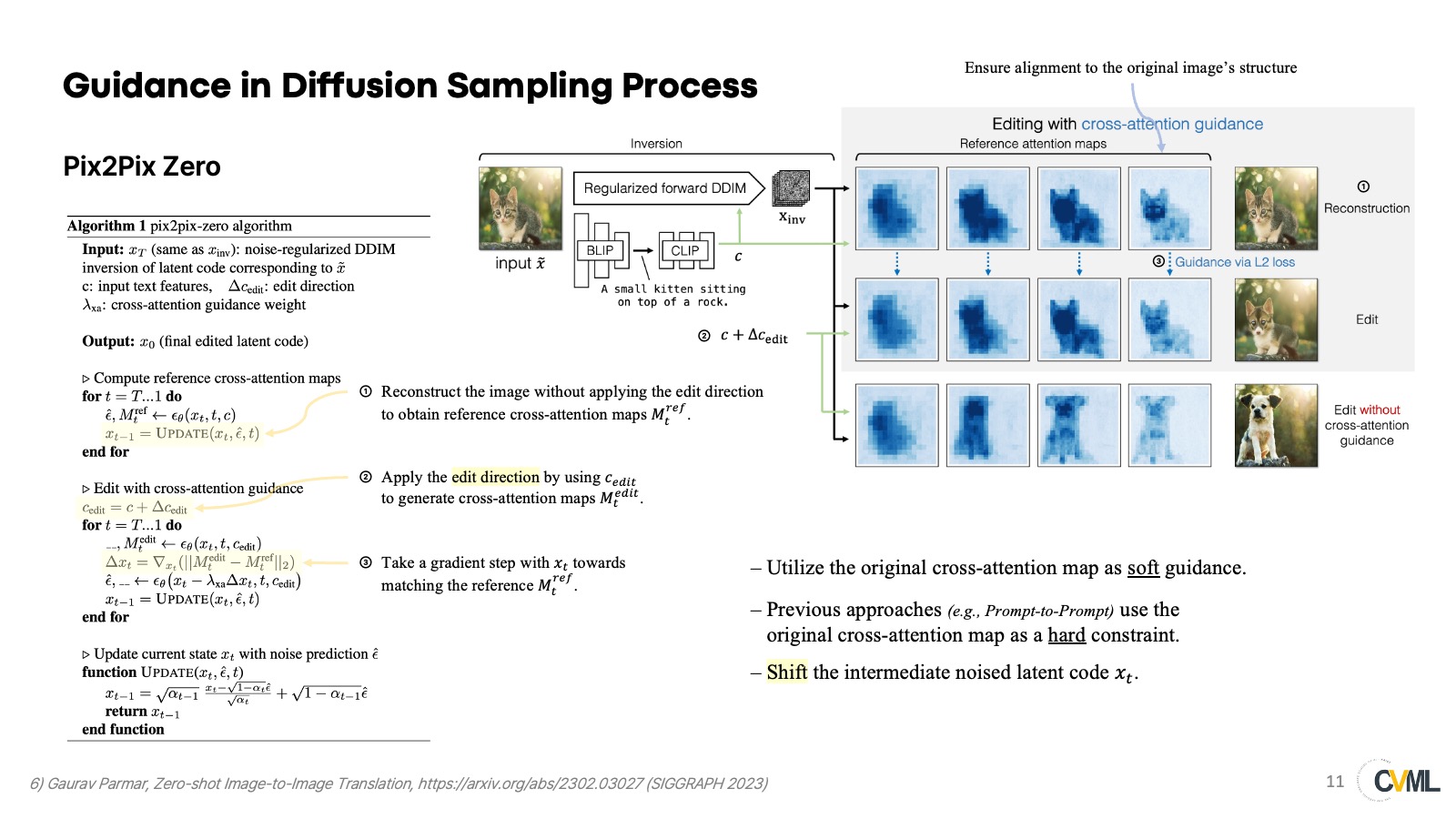
그 구체적인 알고리즘을 여기서 소개하고 있다. Cross-attention guidance를 사용하여 latent code인 $z_t$를 shift 시킨다. 논문에서는 $x_t$라고 소개하고 있긴 한데, 단순 notation의 차이라고 생각하며 실제 코드 상에서 분석했을 때도 diffusers의 stable diffusion pipeline을 그대로 따라가므로 latent code를 shift 시킨다고 보는 게 맞을 것 같다. 또한, 이 논문에서 cross-attention guidance를 기존의 word swap 또는 prompt refinement를 수행하는 prompt-to-prompt와 달리 soft-guidance를 취한다고 말하고 있다.
Summary
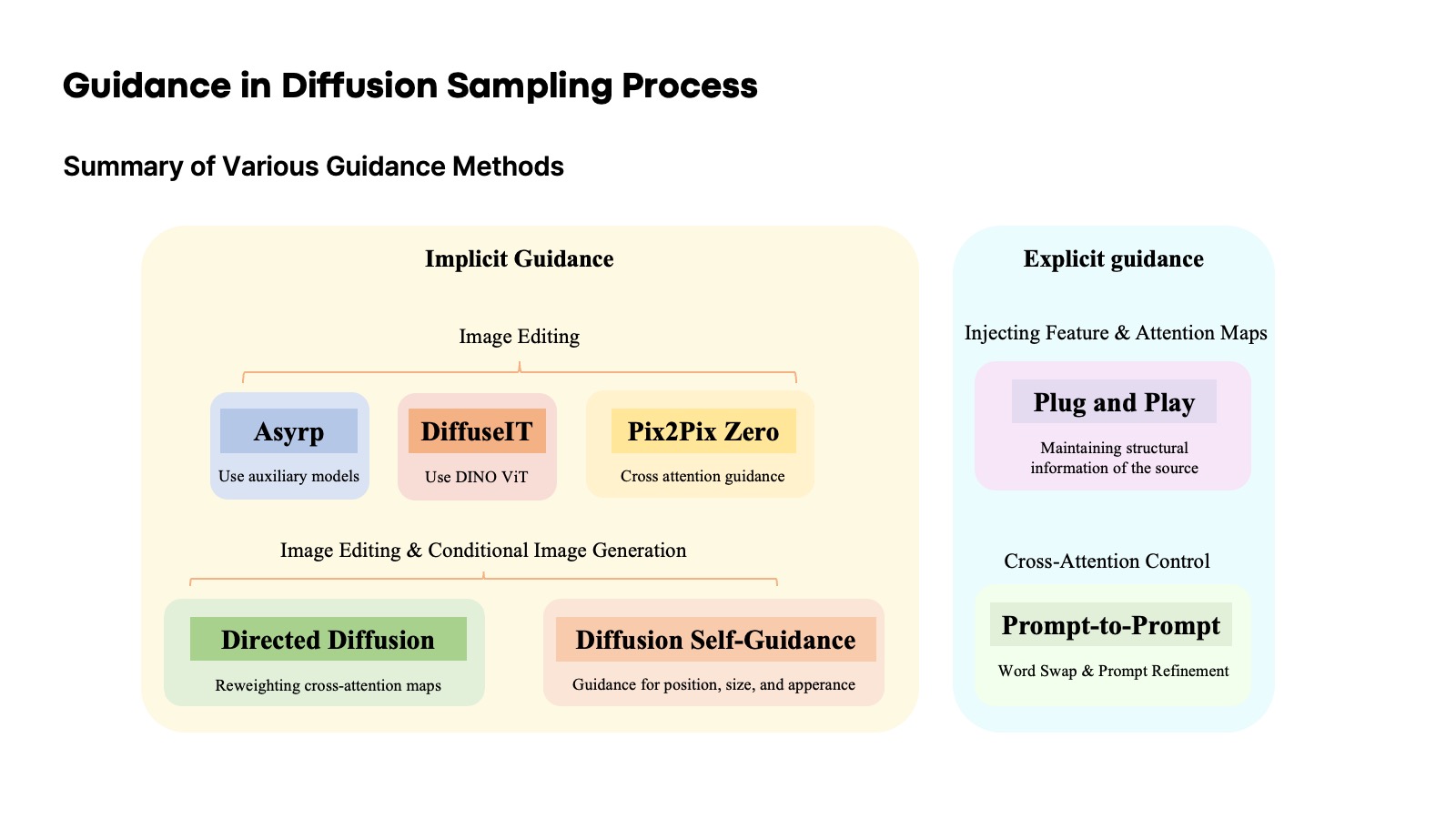
지금까지 소개한 연구들의 공통점은 latent code, prediction, noise 등 무언가를 원하는 방향으로 shift 시키고 있다는 게 특징이다. 특히, Asyrp처럼 부가적인 network나 ControlNet 같이 fine-tuning을 하지 않고 단순히 energy function만을 정의해서 shift 시키는 Pix2Pix Zero, Diffusion Self-Gudiance 등 연구들이 주목할 만하다는 생각이 들었고, 그래서 필자도 conditioning에 맞게 원하는 이미지를 생성하거나 editing 할 때 어떤 새로운 objective를 정의함으로써 그러한 방법을 구현할 수 있겠다는 생각이 들었다. 그렇지만 사실 editing 자체로만 보면 이제까지 많은 선행연구들이 있어왔기에 novelty가 부족하다는 우려가 들었고, 단순히 image-editing에 대한 energy function을 제시하는 것을 넘어서 기존의 stable diffusion이 취약했던 부분인 conditional multi-labeled objects generation를 중점으로 연구를 진행 중이다. 그에 맞는 설계를 바탕으로 가설에 맞게 결과가 나오는대로 논문을 내려는 계획이다. 자세한 내용은 이 프로젝트를 참조하면 된다.
Reference
1) Jiaming Song et al., “Denoising Diffusion Implicit Models.” arXiv:2010.02502 (2020)
2) Robin Rombach et al., “High-Resolution Image Synthesis with Latent Diffusion Models.” arXiv:2112.10752 (2021)
3) Mingi Kwon et al., “Diffusion Models already have a Semantic Latent Space.” arXiv:2210.10960 (2022)
4) Gihyun Kwon et al.,“Diffusion-based Image Translation using Disentangled Style and Content Representation.” arXiv:2209.15264 (2023)
5) Dave Epstein et al., Diffusion Self-Guidance for Controllable Image Generation, arXiv:2306.00986 (2023)
6) Gaurav Parmar, Zero-shot Image-to-Image Translation, arXiv:2302.03027 (SIGGRAPH 2023)